알고리즘을 시작하기 전에 자료구조라는 것을 알아야한다고 해서 봤는데,
정보처리기사 따던 시점에 봤던 말들이 나와있어서 좀 반가웠다.
그런 김에 복습 겸 살짝 정리해보고자 한다.
1) Queue (큐)
Queue는 위 아래 구멍이 뚫려있는 원통으로 생각해보면 좋다. 일단 정보처리기사를 공부하던 나는 이렇게 이해했고,
교재에서도 제시하니 가장 명확한 설명이 아닐까 싶다.

위의 그림과 같이 Queue는 입구와 출구가 정해져있다.
한쪽으로는 데이터를 꺼내고, 한쪽에서는 데이터를 넣기만 하도록 구조를 잡는다고 보면 된다.
이런 모양을 가지고 있게 되면 처음 넣은 요소가 꺼낼때도 가장 처음으로 나오게 되는데 이를
'FIFO' (First In First Out)
라고 부른다.
쉽게 이해하기 위해 JS 코드로 한번 들여다보자.
const queue = ['data1','data2','data3']; // queue 선언
queue.push('data4'); // 'data4'라는 string 데이터 queue에 삽입.
const valueFromQueue = queue.shift(); // 배열 내에 들어있는 첫번째 밸류를 꺼내옴. 즉 'data1'JS 에는 따로 명확히 Queue니 Stack이니 이 배열이 어떤 자료구조에 해당하는건지 보여줄 수 있는 것이 없다.
하지만 우리는 데이터를 넣고 꺼내는 방법을 통해 이 배열의 자료구조를 예측할 수 있다.
우선 queue라는 배열을 선언했고 이 배열을 데이터가 담기는 하나의 원통으로 생각해보자.
그리고 push()를 통해 데이터를 삽입하게 되는데, 이 push()는 선언되어있는 배열의 가장 마지막 인덱스에 새로운 요소를 추가한다.
그리고, shift()를 통해 배열 내 가장 첫번째 요소를 꺼낸다.
이것이 queue의 모양새다.
2) Stack (스택)
Stack은 Queue에서 생각한 원통의 출입구 중 한쪽을 막기만 하면 된다.

한쪽이 막히면 데이터의 출입이 모두 한 쪽에서만 이뤄지게 되고 이는 당연히 가장 마지막에 넣은 요소가 가장 먼저 나오는 모양새를 보여주게 된다.
이것은 Queue에서 말한 FIFO가 아닌
'LIFO' (Last In First Out)
이라고 부른다.
이것 역시 코드로 설명해보자.
const stack = ['data1','data2','data3']; // stack 선언
stack.push('data4'); // 'data4'라는 string 데이터 queue에 삽입.
const valueFromStack = stack.pop(); // 배열 내에 들어있는 마지막 밸류를 꺼내옴. 즉 'data4'
앞선 Queue와 마찬가지로 데이터가 들어가고 나오는 모양을 통해 Stack이라는 것을 예측할 수 있다.
데이터를 삽입하는 것까지는 동일하나,
마지막에 데이터를 꺼내는 함수가 pop()이라는 것을 알 수 있다.
pop()은 배열의 가장 마지막 요소를 꺼내는 함수이다.
마지막에 넣은 요소를 가장 먼저 꺼내고 있으니 이는 Stack이라고 볼 수 있다.
3. Tree (트리)
Tree는 개발을 해본 사람이라면 모두 익숙한 자료구조일 것이라고 생각한다.
Root가 존재하고 그 Root의 자식이 있으며 또 그 자식들 역시도 자식을 가지는 구조.
XML, HTML 모두 비슷한 계층 구조를 띄고 있기 때문에 이해가 어렵지 않을 것이다.
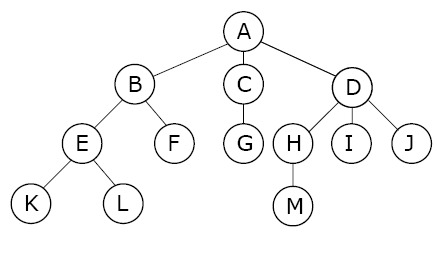
그림으로 그려내면 이런 모양이다.
A가 루트이고, BCD는 A의 자식, EFGHIJ는 BCD의 자식 이런식으로 가지를 치며 Depth를 만들어가기 때문에 Tree구조이다.
그러면 이 트리구조 역시 코드로 나타내어보자.
const tree1 = [[[A],[B],[C]],[[D],[E]],[[F],[G],[H]]]
const tree2 = {
A: {
B: 'A',
C: 'B',
},
B: {
D: 'C',
E: 'D',
},
}이것들도 트리의 모습이다.
첫번째는 3차원 배열이다.
가장 바깥을 싸고 있는 배열이 Root일테고 두번째 Depth의 배열들이 그 자식들이다.
그리고 세번째 Depth에 들은 배열들이 그 자식들의 자식들이다.
즉, 배열은 한차원씩 차원이 늘어날 수록 Depth가 깊어지는 Tree라고 보면 되겠다.
두번째는 Object로 만들어봤다.
Object 역시 field로 또다른 Object가 생긴다면 Depth가 생기기 때문에 이 역시도 Tree라고 보면 된다.
그리고 알고리즘은 주어진 이 자료구조들을 적절히 이해하고 활용해서
원하는 값을 도출하는 로직인 것이다.
'Dev > Algorithm' 카테고리의 다른 글
| [코딩테스트] 안전지대 (1) | 2023.05.19 |
|---|---|
| [코딩테스트] 다항식 더하기 (0) | 2023.05.17 |
| [코딩테스트] 직각삼각형 출력하기 (0) | 2023.04.14 |
| [코딩테스트] 최빈값 구하기 (0) | 2023.04.14 |
| [코딩테스트] 분수의 덧셈 (0) | 2023.04.14 |